Unicode, Unicode, Unicode!
2025-04-05
I am becoming increasingly a fan of emojis. You'll have noticed they are used profusely across the site - along with small icons where there isn't an appropriate symbol available -.
So... Have you ever wondered where all these symbols come from?

"ZXSpectrum48k" by Bill Bertram is licensed under CC BY-SA 2.5.
Once upon a time we had computers with very small memories. A typical home computer could have as little as 48KB of memory, that is less than the size of most Microsoft Word documents or just the background image of this page.
It's not hard to understand that at that time you had to store everything in a very compact manner. In the case of text, the most popular way was the ASCII code.
In this code each character is codified using less than one byte, that is the smallest unit a computer can usually store. A byte is equivalent to a number between 0 and 255, and the ASCII code works by assigning each character one number between 0 and 127. For example the code for 'A' is 65, for 'B' 66 and so on. Here's the complete ASCII table.
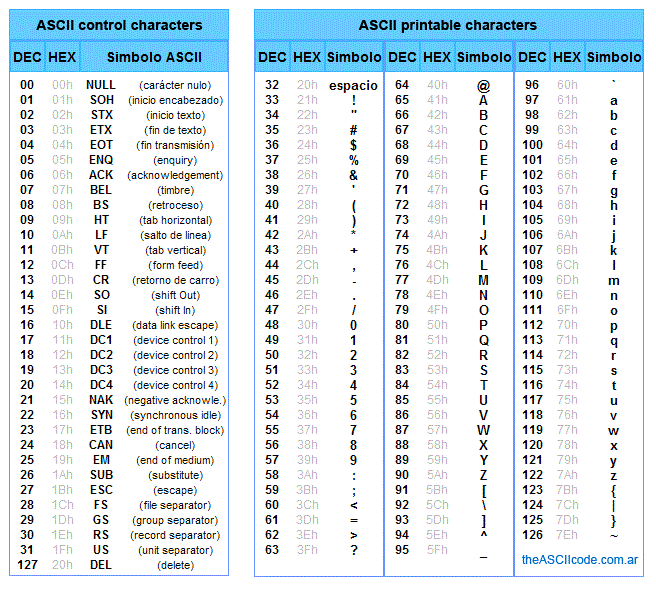
"Ascii-codes-table" by Yuriy Arabskyy is licensed under CC BY-SA 3.0.
As you'll have noticed, only characters from the English alphabet are available. That is not surprising because ASCII means American Standard Code for Information Interchange.
But time went by and computers increased their capacity dramatically. We moved from KB to MB, and then to GB, roughly a million times more in just a few decades. At the same time, computers started to be used by people from around the world. Not only scientists and computer experts, but ordinary people that wanted to read and write text in their own language.
As an intermediate solution, some companies started to use the 128 numbers that ASCII left unused to codify symbols of different languages. Those are called "code pages" and literally hundreds of them were developed. There is one for Spain, one for Germany, one for Romania... Its advantage is that characters still occupy one byte, but the problem is that the codepages are not compatible between them.

"20180927-RD-LSC-0933" by USDAgov is marked with Public Domain Mark 1.0.
By the way, that's one of the reasons you have to define the language you are going to use when you configure your computer for the first time.
But why this obsession with one-byte characters when you have a computer with 16GB of Memory? That was what the Unicode Consortium thought when they designed Unicode: one codification to rule them all.
Unicode works by assigning each character four bytes. It doesn't seem much but if with one byte we can codify up to 256 characters, with four we can codify more than four million. That is enough for English, Japanese, Chinese... Well, it's enough to codify any language in the world really, and there's still plenty of room.
Problem is, empty space is not something humans like, and soon some people started to wonder "What could we codify with those numbers?".

"iPhone: Emoji Keyboard enabled" by schoschie is licensed under CC BY-SA 2.0.
The answer is, as you'll have guessed by now: all these symbols you use when you are chatting with your friends or when you are browsing this site. Smileys, people hugging, hearts, a Spanish dancer... In fact, each year more symbols are added.
So, you have been using Unicode a lot without probably knowing it! And now that you know, maybe you'll become a fan too.
No AI has been used to generate this text.